
——從「把模型餵更大」的擴展定律,轉向「讓模型更像在理解與預演現實」的世界模型路線。
1) 為什麼「越大越好」開始失靈?
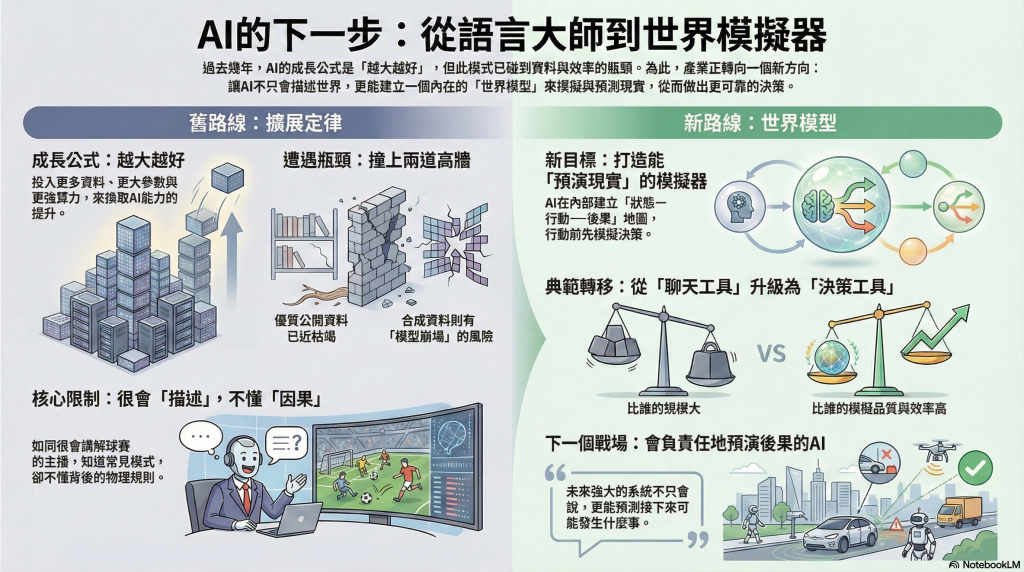
過去幾年來,我們都已經習慣AI 越大越好:資料更多、參數更大、算力更猛 → 能力就上升。
GPT-3 → GPT-4 這條路線有效,是因為「文字世界」夠大、訓練方法夠粗暴、而且回報還很甜。
但現在遇到兩道牆:
- 資料牆(Data Wall):公開網路資料有限,好的資料更有限。
- 合成資料的副作用:合成可以補洞,但也可能把偏誤與錯誤「複印再複印」,形成你提到的 模型崩塌(像影印機一直影印影印,最後只剩噪點)。
所以問題不是 LLM 不夠聰明,而是它「吃的營養」與「訓練目標」開始卡住上限。
2) LLM 的本質限制:它很會接龍,但不等於懂因果
LLM 會把語言裡常見的共現關係(玻璃、掉落、碎裂)學得爐火純青,但它未必有「重力」「脆性」「碰撞」這種 可用來推演的因果模型。換句話說,LLM 目前像一個超級強的文字統計引擎:
它知道「人類通常怎麼描述世界」,但不一定知道「世界怎麼運作」。
這就是為什麼很多時候它看似會推理,但在一換場景、缺少語料提示時,就會出現很有信心的胡說八道(幻覺),因為它在做的仍是「語言上的合理延伸」,不是「物理/因果上的可驗證推演」。
3) 世界模型(World Model)想改變的不是畫質,而是“可行性”
世界模型的重點不是生成更逼真的畫面,而是理解什麼在現實中「可能」或「不可能」。
這句話其實是在講一個新的能力:
AI 不只回答「接下來一句話」,而是能在內部建立一個「狀態—行動—後果」的地圖,先模擬再決策。
它強調的那幾個關鍵詞(3D 空間、物理定律、物體恆存、行動後果),本質上是要讓模型具備**可用於規劃(planning)**的內在表徵。
你可以把它想成:LLM 是「很會講解球賽的主播」,世界模型是「真的會踢球的球員」。主播懂敘事,球員懂動作與後果。
4) 典範轉移的標誌:AI 從「聊天機器人」走向「模擬器」
在工廠場域的例子很好:
- 文字標示「危險區域」只是符號
- 世界模型要做的是:理解進入後可能發生什麼(被夾、被撞、觸發警報、影響產線節拍),並能在行動前做風險評估
所以它是在把 AI 從「描述工具」升級成「決策工具」。
5) 新擴展定律:衡量標準換成「模擬品質」與「效率」
這段其實點到產業會很在意的兩件事:
- KPI 改了
不再是「參數多大、資料多少」,而是 - 模擬是否一致
- 預測未來狀態是否可靠
- 對環境變化是否泛化(不靠背題)
- 能源與效率的敘事改了
傳統生成(尤其影片/多模態)如果要逐像素預測,成本非常高。
世界模型若能學到「抽象表徵」——抓關鍵狀態、忽略不重要細節——就有機會在訓練與推理上更省。
這裡的比喻「開車看路況,不用在意每朵雲」很到位:人類能高效行動,是因為我們把世界壓縮成可決策的關鍵變數,而不是把所有像素都算一遍。
6) 你可以怎麼把這篇文章轉成「可落地的洞察」(以你常跑的製造業為例)
用很務實的語言講,這篇在暗示企業下一波競爭力可能不是「買到最強 LLM」,而是:
- 你能不能把現場變成可被模擬的系統(設備狀態、工序約束、空間安全、物流路徑、能耗模型)
- 你能不能把知識庫(RAG)從“查答案”升級成“做決策”
- 查答案:SOP 怎麼寫、規範怎麼做
- 做決策:在某種狀態下,下一步怎麼做才安全、才不延誤、才省能耗
很直白地說:沒有結構化的現場資料 + 約束條件(constraints),世界模型只是很潮的字。一旦你把資料與約束建起來,它才會變成「會思考的數位分身」。
7) 再「理性補一刀」
這種敘事很合理,但也要小心兩個點:
- 世界模型不是銀彈:真實世界充滿噪音、缺資料、感測錯誤、未知干擾;模型再會模擬,也要面對「現場永遠比簡報髒」的宇宙真相。
- 短期內更可能是混合路線:LLM(語言、規範、知識)+ 世界模型(狀態、空間、因果)+ 驗證器/規則引擎(安全與合規)一起上,才會變成企業可用的系統。
所以把它當成一個工作假說最健康:下一波 scaling 可能靠「模擬能力」擴展,而不只是文字 token。但要落地,得靠資料、感測、流程建模與驗證機制一起補齊。
總結一句: AI 的成長方式正在從「吃更多文字」改成「更像在腦中跑實驗」。未來強的系統不只是會講,而是能告訴你「接下來可能發生什麼、為什麼、以及怎麼做比較安全/有效率」。
宇宙很冷酷,但也很公平:會聊天的 AI 已經很多了;會負責任地預演後果 的 AI 才是下一個戰場。
